A brit adatvédelmi biztos (Information Commissioner´s Office, ICO) konzultációra közzétett egy iránymutatást, amely a generatív mesterséges intelligencia rendszerek (GenAI) webről gyűjtött adatokkal történő tanításának feltételeivel foglalkozik. A téma jelentőségét az adja, hogy a generatív MI rendszerek tanítása tipikusan rengeteg adatot igényel, amely adatok összegyűjtése gyakran történik nyilvánosan elérhető forrásokból, így különösen az internetről. Az interneten hozzáférhető adatok (beleértve a személyes adatokat, illetve akár más védett kategóriába tartozó adatokat, pl. szellemi alkotásokat) felhasználása nem magától értetődő, a jogszerű felhasználás feltételeinek megteremtéséről gondoskodni kell.
Nem az ICO az első adatvédelmi hatóság, amely a témával foglalkozik. A francia adatvédelmi hatóság (CNIL) tavaly októberben tett közzé útmutatót az MI rendszerek fejlesztésének adatvédelmi kérdéseiről, amely az adatkezelés lehetséges jogalapjait is vizsgálja. A példák között - érintőlegesen - a CNIL útmutatója is érinti - a jogos érdeken alapuló adatkezelés körében - az online elérhető adatok felhasználását az MI rendszer tanítására.
Egyébként a CNIL 2020-ban külön iránymutatásban foglalkozott az online elérhető adatok gyűjtésével (web scraping) és direkt marketing célú további felhasználásával. (Rövid angol nyelvű összefoglaló elérhető itt.)
A web scraping kérdése a Clearview AI-t érintő adatvédelmi hatósági eljárásokban is felmerült, hiszen a cég üzleti modelljének szerves részét képezte a nyilvánosan (online) elérhető képek összegyűjtése és felhasználása.
(A téma nem csak az EU-ban és nem kizárólag a GDPR felől nézve vet fel komoly jogi aggályokat, hanem az USA-ban is több jogvita kapcsolódott hozzá az elmúlt években. Az USA-ban alakuló joggyakorlatról lásd ezt a cikket.)
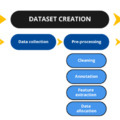
1. A fejlesztés szakaszai
Az ICO iránymutatása a generatív MI rendszerek fejlesztése kapcsán az alábbi lépéseket rögzíti:
- adatgyűjtés,
- az adatok előzetes feldolgozása,
- alapmodell tanítása,
- alapmodell finomhangolása adott felhasználási célra és a modell működésének értékelése,
- a működés értékelése és a tapasztalatok beépítése a modell működésébe.
2. A tréningadatok forrása és jellege
A térningezéshez használt adatok gyakran származnak publikus forrásokból, és az adatok összegyűjtéséhez az ún. "scraping" technika kerülhet alkalmazásra, amely lényegében a különböző webhelyeken elérhető adatok, információk kinyerését és lemásolását jelenti. Ez tipikusan valamilyen automatizált megoldással történik.
Az interneten elérhető és így a "web scraping" célpontját képező adatok között jelentős mértékben lehetnek személyes adatok, amelyek kezeléséhez az adatvédelmi szabályoknak való megfelelés szükséges, beleértve a megfelelő jogalap meghatározását és fennállásának biztosítását.
3. Lehetséges jogalap(ok)
Az ICO véleménye szerint a GenAI rendszerek tanítása céljából az elméletileg szóba jöhető jogalapok közül, érdemben a jogos érdek lehet alkalmazható. (Az ICO természetesen a Brexit miatt az Egyesült Királyságban elfogadott saját adatvédelmi törvény, az ún. "UK GDPR" alapján tárgyalja a jogalapok kérdését, ugyanakkor a UK GDPR és a GDPR tartalmi hasonlósága miatt, az ICO megállapításai az Egyesült Királyság határain kívül is relevánsak lehetnek.)
A CNIL fent hivatkozott iránymutatása több jogalapot is vizsgál az MI rendszerek fejlesztéséhez történő adatkezeléssel összefüggésben, hiszen ezen célú adatkezelések esetében is több jogalap jöhet szóba, ugyanakkor a "web scraping", mint adatgyűjtési technika kapcsán a gyakorlatban valóban a jogos érdek, mint jogalap a leginkább életszerű.
(Természetesen az adatvédelmi követelményeknek való megfelelés mellett az is szükséges, hogy egyéb jogszabályokban, pl. szellemi alkotások védelmére vonatkozó szabályokban, foglalt kötelezettségek se sérüljenek.)
Az ICO megállapítása alapján a jogos érdek - általánosságban - szóba jöhet, mint jogalap a GenAI rendszerek tréningezéséhez történő adatgyűjtés kapcsán, ha az adatkezelést végző szervezet az adatkezelés jogszerűségét megfelelően alátámasztja - a három főbb lépésből álló - érdekmérlegelési teszt keretében:
- az adott esetben fennálló jogos érdek specifikus meghatározása (ami lehet fejlesztői üzleti érdek és ezen túlmutató, szélesebb társadalmi érdek is, függően a tervezett felhasználás céljától és módjától),
- szükségességi teszt: a webről gyűjtött nagy mennyiségű adat valóban elengedhetetlen a fejlesztéshez (a technológia állásától és a konkrét fejlesztés körülményeitől tehető függővé a szükségesség),
- érdekek kiegyensúlyozása: az érintettekre gyakorolt hatás vizsgálata és miként egyensúlyozhatók ki az érintetteket érintő esetleges negatív hatások, különösen a "web scraping" jellegéből, mint az érintettek számára tipikusan "láthatatlan" adatkezelésből eredő kockázatok. A kockázatok között felmerülhetnek az érintettek joggyakorlásával összefüggő kockázatok, illetve a fejlesztett modell felhasználásával kapcsolatos kockázatok, mint pl. visszaélésszerű tartalom generálása, hackerek, adathalászok általi felhasználás lehetősége, stb. A kockázatok kezelése kapcsán szóba jöhető megoldások nagyban függenek attól, hogy miként történik a modell felhasználása:
- maga a fejlesztő teszi közzé a modellt a saját platformján: ez nagyobb kontrollt jelent a fejlesztő részére és - ha társadalmi célok megvalósítására alapozták a jogos érdeket - akkor a fejlesztőnek kontrollálnia és igazolnia kell, hogy a felhasználás tényleg erre a meghatározott társadalmi célra történik; az egyénre leselkedő kockázatokat értékelnie kell; megfelelő technikai és szervezési intézkedéseket kell alkalmaznia;
- a modellt nem az eredeti fejlesztő, hanem egy harmadik fél használja API-n keresztül: ha a fejlesztő ún. API-n keresztül teszi elérhetővé a modellt harmadik felek számára, amely harmadik fél magához a modellhez nem fér így hozzá ("closed-source approach"), akkor a fejlesztőnek gondoskodnia kell arról, hogy a harmadik fél úgy használja a modellt, hogy az eredetileg meghatározott jogos érdek (amihez az adatokat a "web scraping" során gyűjtötték) ne sérüljön (az eszközök között technikai megoldások és szerződéses kikötések is szerepelhetnek);
- a modell vagy érdemi részletek a modell működéséről elérhetőek harmadik fél (felek) számára: a fejlesztőnek ebben az esetben jóval kevesebb kontrollja van a tényleges alkalmazás kapcsán, a szóba jöhető szerződéses korlátozások az esetleges felasználás kapcsán nem feltétlenül érvényesülnek maradéktalanul, illetve kérdéses, hogy a fejlesztő ezek betartását mennyire tudja érvényesíteni és ellenőrizni (mindazonáltal elvárás a fejlesztők felé, hogy igazolni tudják a kontrollok érvényesülését a gyakorlatban).
Összességében az adatok generatív MI fejlesztése céljára, "web scraping" útján történő gyűjtése jogszerű lehet, de a fejlesztőknek körültekintően, az adatvédelmi szabályoknak megfelelően kell eljárniuk és az alkalmazott technikai és szervezési intézkedéseket is a konkrét adatkezelés jellegének megfelelően kell kialakítaniuk.
Az ICO iránymutatása még változni fog a konzultáció eredményeképpen, így mindenképpen érdemes figyelemmel kísérni a fejleményeket, ugyanakkor egyéb (pl. a CNIL által közzétett) MI-specifikus iránymutatásokkal együtt már ebben a fázisban is nagy segítséget jelenthet a jogszerű adatkezeléshez. A most konzultcáióra közzétett iránymutatás egy konzutlációs sorozat első eleme, amelyet rövidesen további anyagok követhetnek.